
Article note
Authentication
Authentication is the process of verifying the identity of a user or system. By performing authentication we can add needed context to the requests. AWS AppSync supports several authentication types:
API_KEY,AWS_LAMBDA,AWS_IAM,OPENID_CONNECT,AMAZON_COGNITO_USER_POOLS.
In case of this application AMAZON_COGNITO_USER_POLLS is chosen as the primary authentication type. Amazon Cognito is a fully managed identity and user management service. It provides an option to create user pools which are a user directories. Let's start by creating a user pool in serverless framework. Config used for this user pool sets a policy for a password (minimum length of 8) and user attributes.
UserPool:
Type: AWS::Cognito::UserPool
Properties:
AutoVerifiedAttributes:
- email
Policies:
PasswordPolicy:
MinimumLength: 8
RequireLowercase: false
RequireNumbers: false
RequireUppercase: false
RequireSymbols: false
UsernameAttributes:
- email
Schema:
- AttributeDataType: String
Name: name
Required: false
Mutable: trueWith this defined, the next step is linking it to the AppSync API.
authentication:
type: AMAZON_COGNITO_USER_POOLS
config:
userPoolId: !Ref UserPoolSecondary authorizer
This app is an example of an online store. Some operations, like placeOrder, should only be done by admins or logged-in users, while others should only be available on the frontend. To handle this, feature of AppSync can be used that allows having multiple authorizers. In this case, an API key will be used to let the frontend connect to AppSync and run queries. It's a good idea to regularly rotate API keys, so a 1-month expiration time was set for this one.
additionalAuthentications:
- type: API_KEY
apiKeys:
- name: WebClientApiKey
expiresAfter: 1MWhen both authorizers are defined, the GraphQL schema can be updated to reflect those changes. By default, when multiple authorizers are specified and the schema doesn't use directives to specify which field, query, or mutation should be used by which authorizer, AppSync assumes that the default authorizer will be used for all of them. This means it is not possible to access any of them using secondary authorizers. So in case of queries getProducts and getCategories should be allowed to be executed by both logged-in and not logged-in users. getOrders should only be executed by logged-in users. That's why, under the query declaration, no schema directive is used, and the query defaults to the default authorizer.
type Query {
getProducts: [Product!]
@aws_api_key @aws_cognito_user_pools
getCategories: [Category!]
@aws_api_key @aws_cognito_user_pools
getOrders: [Order!]
}Authorization
Authorization is the process of determining and granting permissions to a user or system to access specific resources or perform certain actions. It defines what an authenticated user is allowed to do within a system. In case of this application some mutations like placeOrder should be allowed to be executed by all logged-in users while others like createProduct only be a specified group of users, for example administrators.
Authorization can be achieved by first creating a user group in Cognito User Pools and then specifying operations in the GraphQL schema that should only be invoked by members of this group by appending schema directives.
Let's start with creating user group
AdminGroup:
Type: AWS::Cognito::UserPoolGroup
Properties:
GroupName: Admins
UserPoolId: !Ref UserPoolLet's update graphql schema, bear in mind that name of the group in schema must match name of the group specified in cognito configuration.
type Mutation {
placeOrder(input: OrderInput!): Order!
createProduct(input: ProductInput!): Product!
@aws_cognito_user_pools(cognito_groups: ["Admins"])
createCategory(input: CategoryInput!): Category!
@aws_cognito_user_pools(cognito_groups: ["Admins"])
startProcessingOrder(id: ID!): Order!
@aws_cognito_user_pools(cognito_groups: ["Admins"])
completeOrder(id: ID!): Order!
@aws_cognito_user_pools(cognito_groups: ["Admins"])
}Applying least-privilege permissions to IAM roles
When creating set of permissions to roles to attached to lambdas or other resources, grant only the ones that are need to perform a task. This way even if something goes wrong there's a smaller chance that unwanted operations will be spread across more resources.
Example of limited set of privileges attached to lambda:
products:
handler: src/functions/field/products/products.handler
environment:
PRODUCT_TABLE: !Ref ProductTable
iamRoleStatements:
- Effect: Allow
Action:
- dynamodb:GetItem
Resource: !GetAtt ProductTable.ArnExample of non limited set of privileges attached to lambda:
products:
handler: src/functions/field/products/products.handler
environment:
PRODUCT_TABLE: !Ref ProductTable
iamRoleStatements:
- Effect: Allow
Action: "*"
Resource: "*"Mitigating malicious operations
Limiting query depth
GraphQL allows clients to request data in multiple ways, offering various entry points. This flexibility enables the creation of exceptionally large and nested queries, such as the following example where
query NestedQueryExample {
getProducts {
categories {
products {
categories {
products {
categories {
# And this goes on and on...
}
}
}
}
}
}
}This can be easily fixed in AppSync by specifying queryDepthLimit property.
queryDepthLimit: 3Rate limiting
API rate limiting is a technique used to control the number of requests a client can make to an API within a specific time frame. It helps prevent abuse, ensures fair usage, protects against DDoS attacks, and maintains the overall performance and reliability of the API. By setting limits, such as 1000 requests per hour, developers can manage traffic effectively and provide a better experience for all users.
This can be achieved by using AWS WAF service. AWS WAF (Web Application Firewall) is a security service provided by Amazon Web Services that helps protect web applications from common web exploits and attacks. It allows you to create custom security rules to block or allow specific traffic patterns, such as SQL injection, cross-site scripting (XSS) or enabling rate limiting.
Example of enabling WAF:
waf:
enabled: true
rules:
- throttle # limit to 100 requests per 5 minutes periodMore advanced configuration can also be passed:
waf:
enabled: true
rules:
- throttle:
limit: 200
priority: 10
aggregateKeyType: FORWARDED_IP
forwardedIPConfig:
headerName: 'X-Forwarded-For'
fallbackBehavior: 'MATCH'Disabling schema introspection
Disabling schema introspection in a production environment is a security best practice often implemented to protect sensitive information about the application's GraphQL schema. Schema introspection allows clients to query the schema itself, revealing details such as data types, field names, and relationships. While useful in development for debugging and client-side tooling, exposing this information in production can potentially aid attackers in understanding the structure and vulnerabilities of the API. By disabling schema introspection, developers reduce the attack surface and mitigate the risk of unauthorized access or exploitation of the GraphQL API.
This can be achieved by specifying introspection property.
introspection: falseObservability and monitoring
On the aws docs GraphQL documentation site, such a definition is mentioned:
Monitoring is the process of collecting data and generating reports on different metrics that define system health. Observability is a more investigative approach. It looks closely at distributed system component interactions and data collected by monitoring to find the root cause of issues. It includes activities like trace path analysis, a process that follows the path of a request through the system to identify integration failures. Monitoring collects data on individual components, and observability looks at the distributed system as a whole.
Following this definition let's look at
Observability
One of the services that enables to have a observability in a system is an AWS X-Ray. AWS X-Ray is a service that helps developers analyze and debug applications. It provides an end-to-end view of requests as they travel through different components of an application, helping to identify performance bottlenecks, errors, and dependencies across services.
In order to enable X-Ray in AppSync xrayEnabled property must be specified.
xrayEnabled: trueWhen X-Ray we can introspect each trace from aws console.
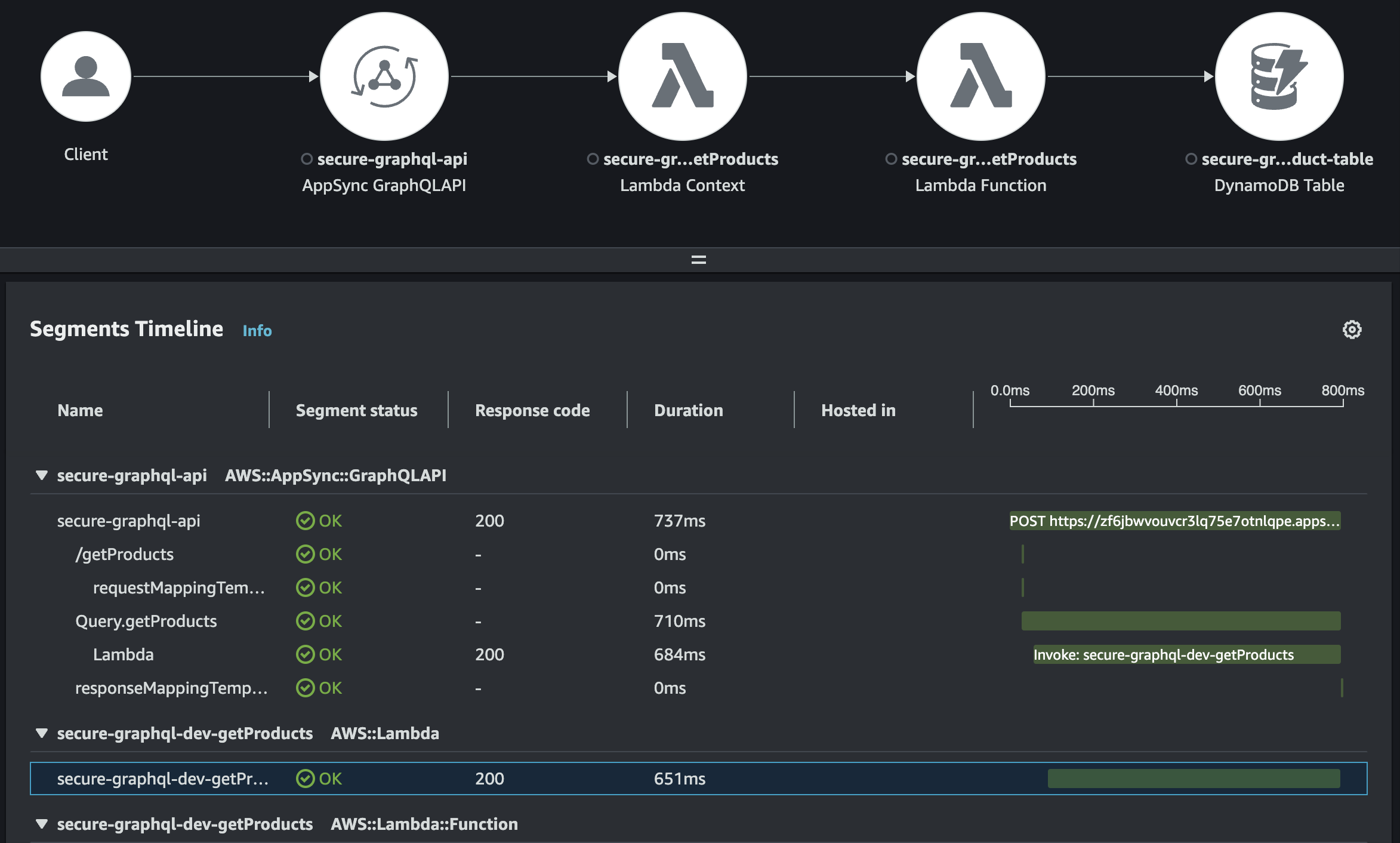
Monitoring
Individual components such as Lambda can be monitored with the help of AWS CloudWatch.
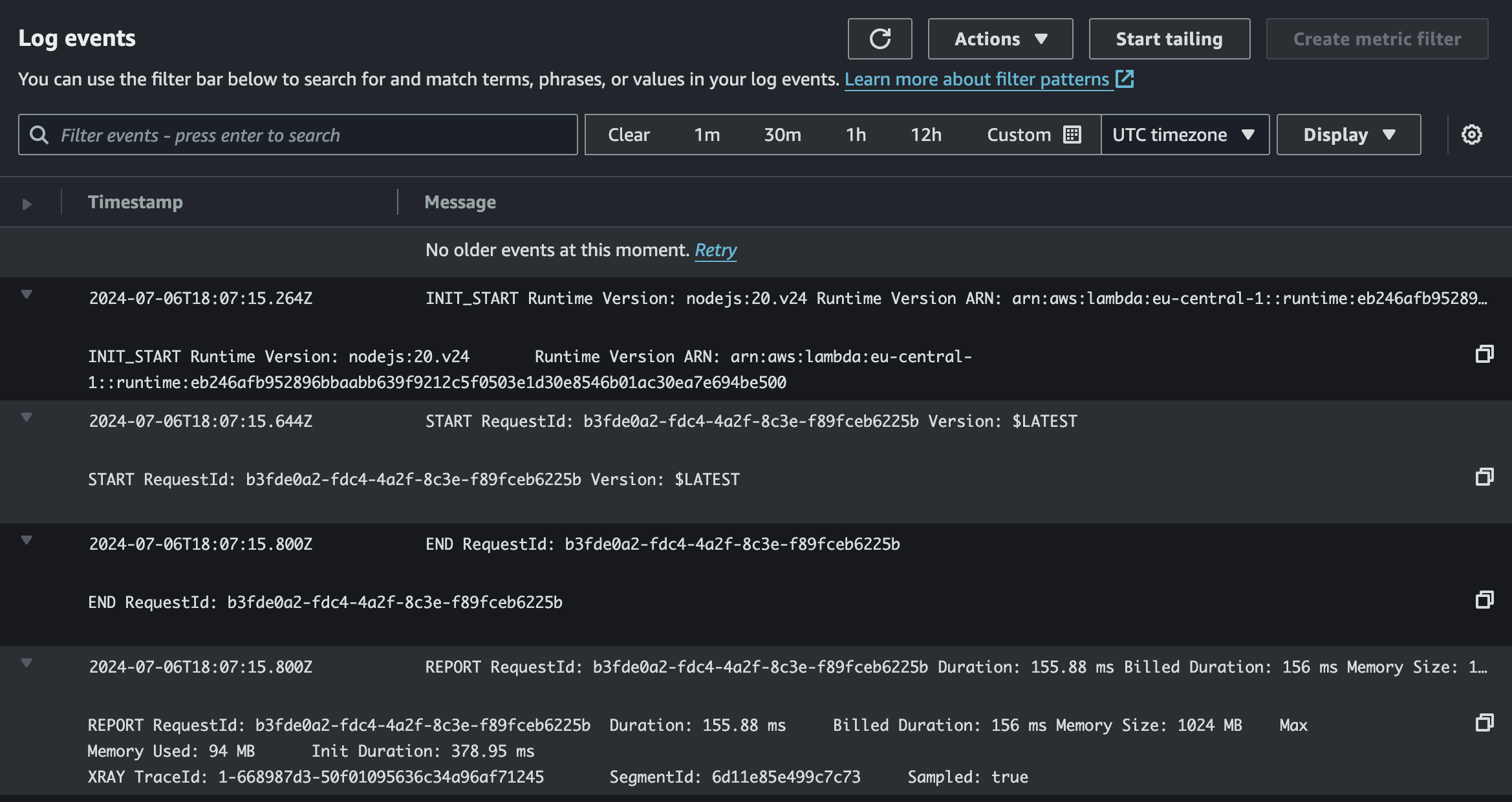
Conclusions
Security is a far more complex subject then what was described here. With that being said guidelines described in this article are a nice starting point in making the apps that you build production ready.


