
Article note
What is GraphQL
On the official GraphQL documentation site, such a definition is mentioned:
GraphQL is a query language for your API, and a server-side runtime for executing queries using a type system you define for your data. GraphQL isn't tied to any specific database or storage engine and is instead backed by your existing code and data.
Let's break down this definition.
Query language for your API
Most query languages, such as SQL, are typically used to query a specific datastore, like a MySQL database. However, GraphQL differs in that it is used to query against an API rather than a specific datastore. This means that in order to fetch data from API you must write a query that selects set of data to be returned.
Below sample query is presented where data about dragon is fetched.
query Dragon($id: ID!) {
dragon(dragonId: $id) {
name
specie
}
}Server-side runtime
This part refers to the runtime provided by GraphQL, emphasizing that it runs on the server. There are several runtime implementations in languages such as Node.js, Java, Kotlin, C#, and many others.
GraphQL isn't tied to any specific database or storage engine
This means that GraphQL itself does not mandate the use of a particular database or storage technology.
With GraphQL, the server defines a schema that describes the types of data available and the operations that can be performed on that data. Clients can then query this schema to request the specific data they need, without being concerned about the underlying data sources.
This decoupling between the GraphQL schema and the data sources gives developers flexibility in choosing the appropriate databases or storage engines for their applications. They can use existing databases, microservices, third-party APIs or any other data source that can be accessed programmatically.
BFF (Backend for Frontends) pattern
Problem statement
Consider an online shopping system that includes both mobile and web applications. Mobile screens are typically smaller than desktop ones. Therefore, when designing the user interface (UI), designers choose to display less data in the mobile version than in the desktop alternative. If the API serving the data is built on the REST architecture and is used by both mobile and desktop applications, the issue of over-fetching often arises. Let's dig deeper into this, consider such a REST API call that display all user orders.
GET /v1/orders
{
"orders": [{
"id": "d6b0b4ed-29b0-42d4-8708-e67e7fa01e8e",
"purchaserEmail": "user@gmail.com",
"status": "CREATED",
"products": [{
"id": "cf4df039-3970-4d4c-99b1-b4563339b168",
"name": "Basketball",
"description": null,
"price": "$20.00",
"created": "2024-03-23T12:30:00.000Z",
"categories": [{
"id": "aa470e5f-2928-45b2-b01f-2ba490737aa7",
"name": "Sports"
}]
}, {
"id": "f932995b-7ddd-4c73-b84d-e9d4a09c261a",
"name": "Football",
"description": "Brand new football, it's the best ball in the whole world",
"price": "$25.00",
"created": "2024-03-20T10:00:00.000Z",
"categories": [{
"id": "aa470e5f-2928-45b2-b01f-2ba490737aa7",
"name": "Sports"
}]
}],
"totalPrice": "$45.00",
"created": "2024-03-24T12:00:00.000Z"
}]
}Look at how much data is fetched just to display a single order. On the web application UI, only fields name, status, created, totalPrice and a breakdown of the ordered products are displayed. On the other hand on a mobile phone, only the status, totalPrice, and created fields are shown, yet all additional data is still fetched. Such a scenario is referred to as over-fetching, where an excessive amount of data is retrieved. This results in network calls that take a long time to execute (due to transferring unnecessary data) and suboptimal memory management on the client's device.
Traditional BFF solution
Looking at the BFF pattern on the microsoft docs, such a definition is mentioned:
Create separate backend services to be consumed by specific frontend applications or interfaces.
That'd mean that essentially mobile app call would look like:
GET /v1/mobile/orders
{
"orders": [{
"id": "d6b0b4ed-29b0-42d4-8708-e67e7fa01e8e",
"status": "CREATED",
"totalPrice": "$45.00",
"created": "2024-03-24T12:00:00.000Z"
}]
}This can be achieved by either having two separate endpoints /v1/mobile/orders and /v1/desktop/orders or implementing API Gateway pattern that'll automatically redirect to mobile or desktop service responsible for serving proper dataset based on requests details.
Both approaches can quickly become suboptimal when new devices, such as iPads, are supported in the future, requiring yet another service that will have a hybrid dataset between the extensive desktop and compact mobile datasets.
GraphQL to the rescue!
Because in GraphQL each client is responsible for declaring fields that needs to be returned by the server this issue is quickly resolved. On server schema is created that defines all possible fields to fetch and then clients selects a subset of them (or if necessary can access all fields). Need for two separate endpoints or services is no longer valid. Example GraphQL queries calls.
query MobileOrders {
orders {
id
status
totalPrice
created
}
}query DesktopOrders {
orders {
id
name
status
created
totalPrice
products {
id
name
price
categories {
id
name
}
}
}
}Helpful Tip
Warning
Building blocks of GraphQL
Schema
The schema serves as a contract between the server and clients, that defines data types available to query and relationships between them. Schema consists out of queries, mutations and subscriptions.
schema {
query: Query
mutation: Mutation
subscription: Subscription
}Types
Type represents a structure of the data. There are scalar types like ID, String, Float or Boolean and complex types like custom objects, Interface, Union or Enum. Type defines the shape of data that can be queried. By default each field in GraphQL is nullable, by appending ! next to the type definition for the field it's marked as not-null field.
enum OrderStatus {
PENDING,
PROCESSING,
COMPLETED
}
type Order {
id: ID!
purchaserEmail: String!
status: OrderStatus!
totalPrice: String!
created: String!
}Query
Queries are used by the clients to fetch data from the server.
# Definition
type Query {
getOrders: [Order!]
}
# Client call
query OrdersQuery {
getOrders {
id
status
}
}Mutations
Mutations are used to modify the data on the server.
input OrderInput {
products: [ID!]!
}
# Definition
type Mutation {
placeOrder(input: OrderInput!): Order!
}
# Client call
mutation PlaceOrderMutation {
placeOrder(input:{ products: ["599256f1-6e03-461e-8cae-bd17ba17c1d3"] }) {
id
}
}Resolvers
Resolvers are functions responsible for fetching the data associated with a particular field in the schema. Let's take for example getOrders query represented in the examples above. For this query we need to specify a resolver that will handle returning orders array.
Sometimes a specific type is referencing other custom type. Let's refactor Order field to contain array of products.
First we define custom Product type.
type Product {
id: ID!
name: String!
description: String
price: String!
created: String!
}No we can reference it in Order type.
enum OrderStatus {
PENDING,
PROCESSING,
COMPLETED
}
type Order {
id: ID!
purchaserEmail: String!
status: OrderStatus!
products: [Product!] # Reference to custom Product type
totalPrice: String!
created: String!
}
# Client call
query OrdersQuery {
getOrders {
id
status
products {
id
name
}
}
}In such a case a nested resolver is a useful concept that can help.
Application goals
In this tutorial, an application will be built based on the previously mentioned online shop example. User can see products, categories and his placed orders. There are 3 queries that can be executed:
getProducts,getCategories,getOrders.
User can place order. Admin can create product or category. Admin can also start processing placed orders and make them completed. For now in this tutorial all mutations are accessible even if user is not an admin. Authentication and authorization of requests is covered in part 2. Given mutations can be executed:
placeOrder,createProduct,createCategory,startProcessingOrder,completeOrder.
Application architecture
Architecture leverages 3 service:
AWS AppSync is a managed service that simplifies process of creating, deploying and managing GraphQL APIs. In AppSync data sources represent the underlying storage or compute services that resolvers interact with to retrieve or manipulate data. AppSync supports multiple data source:
- Amazon DynamoDB,
- AWS Lambda,
- OpenSearch,
- HTTP endpoints,
- Amazon EventBridge,
- Relational databases
- None.
My personal preference is to use AWS Lambda as a data source. Among many others, here are a few key benefits of this approach:
- Custom Business Logic: In my opinion, it's the easiest way to append any custom business logic to your resolvers.
- Easy Testing: It's straightforward to conduct unit testing for Lambda code.
- Developer Experience: In the case of other data types, you are either forced to use VTL files or custom AppSync JS runtime. Traditional Lambda, with support for many tools (such as TypeScript in this tutorial), provides an excellent developer experience compared to other options.
Each query or mutation is connected to the corresponding data source represented by lambda. Lambda then is responsible for performing (if needed) business logic and writing in case of mutations or reading in case of queries to database represented by DynamoDB table. This flow is represented in architecture diagram below.
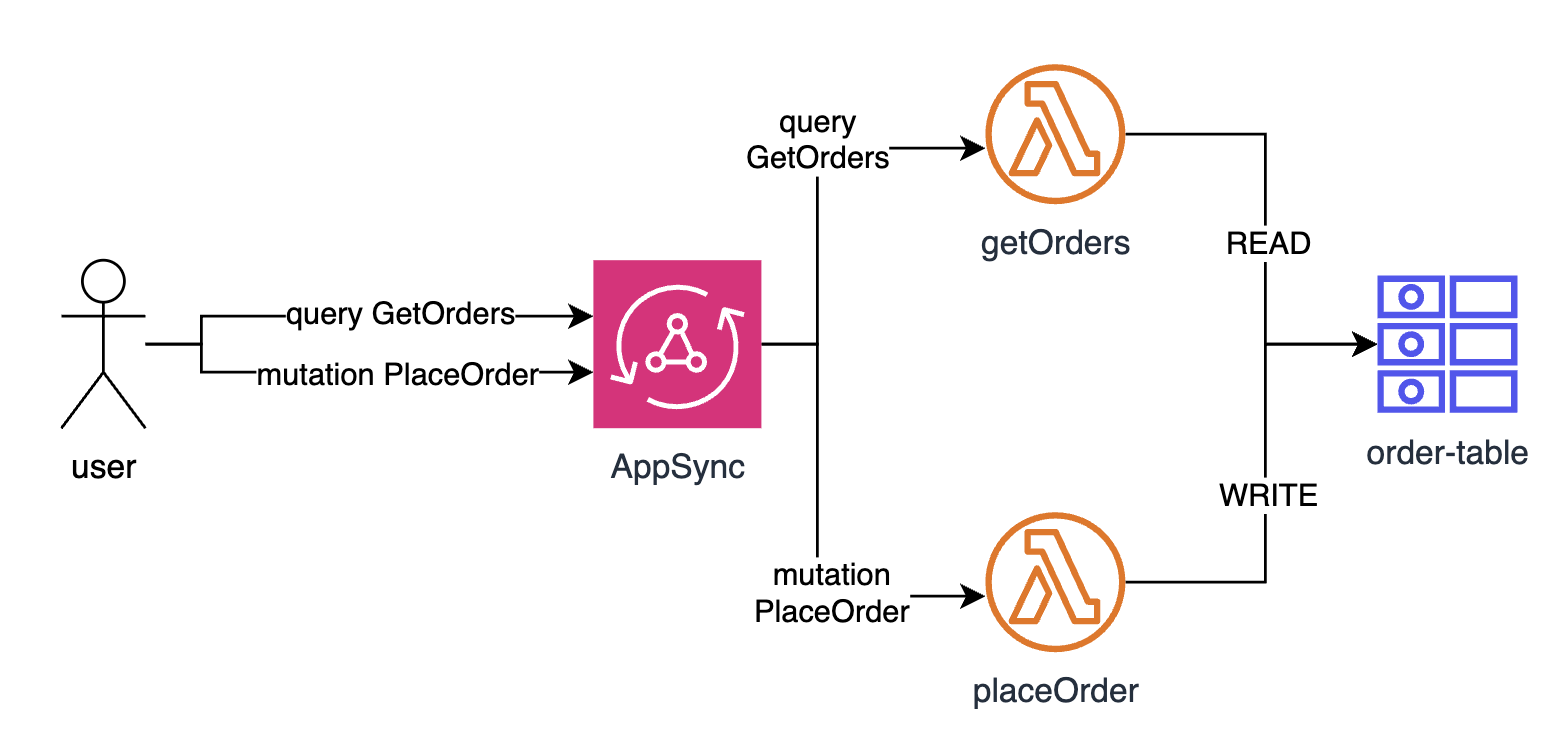
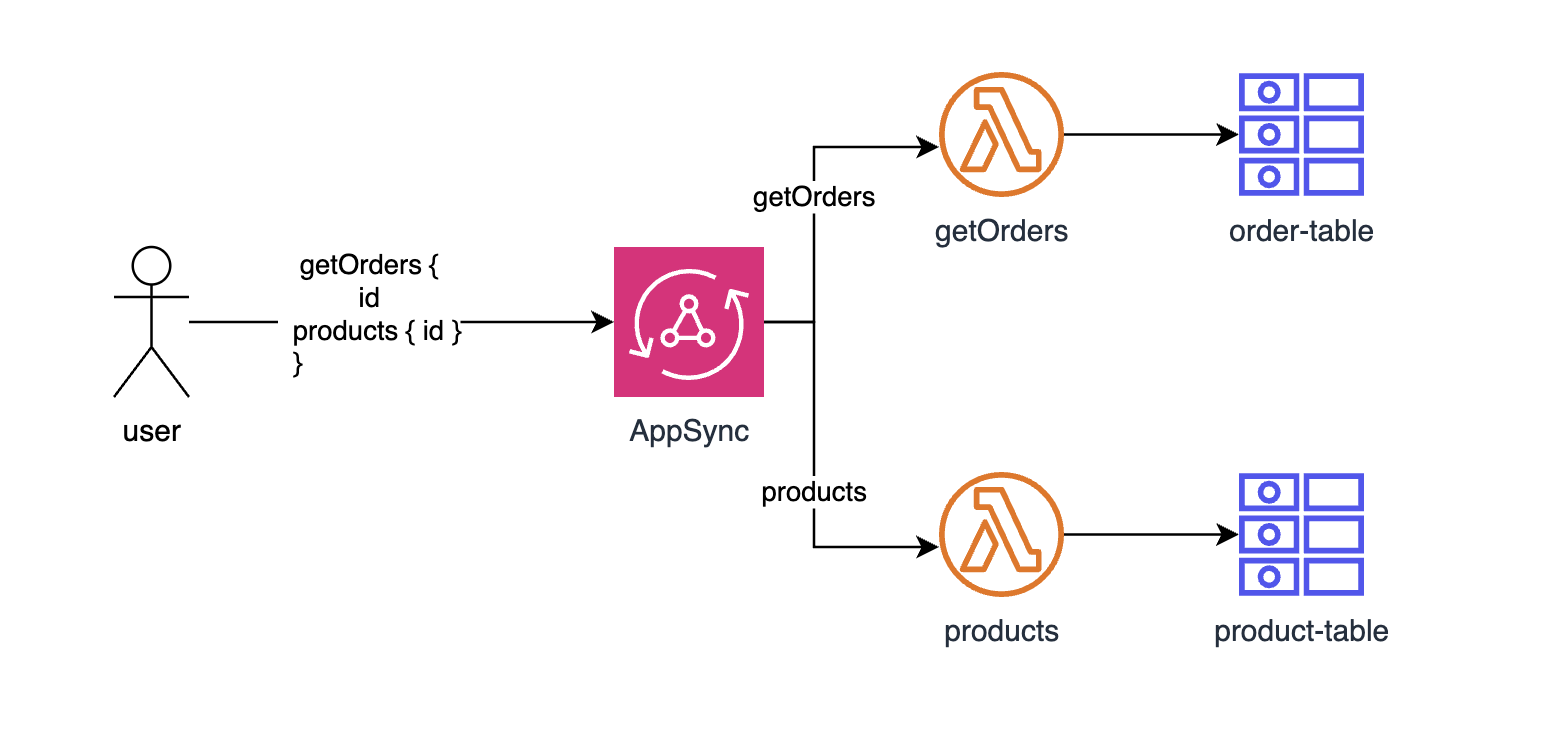
In the case of nested fields AppSync is smart enough to automatically detect if the given nested field is queried. If so, it automatically triggers the resolver responsible for the nested field, which in turn executes the underlying data source with AWS Lambda attached to it. This flow is represented in architecture diagram below.
Schema
Let's begin by designing the schema, which serves as a contract between the server and clients. Based on the fields that we define here, we can later proceed to write resolvers. Let's start by defining types that represent entities within the system. AWS AppSync offers several custom scalars such as AWSEmail or AWSDateTime, which provide more granular control over the specific data types used within the application. You can find more information about all the available AppSync-specific scalars in the dedicated AWS AppSync page.
type Category {
id: ID!
name: String!
products: [Product!]
}
type Product {
id: ID!
name: String!
description: String
price: String!
created: AWSDateTime!
categories: [Category!]
}
enum OrderStatus {
PENDING,
PROCESSING,
COMPLETED
}
type Order {
id: ID!
purchaserEmail: AWSEmail!
status: OrderStatus!
products: [Product!]
totalPrice: String!
created: AWSDateTime!
}Helpful Tip
With our data types represented in the system it's possible to define queries. Notice how query can accept arguments that are used to customize response based on the user needs.
type Query {
getProducts: [Product!]
getCategories: [Category!]
getOrders(email: AWSEmail!): [Order!]
}The next step is to define available mutations. When mutation wants to accept more complex objects as an arguments concept of input can come handy. By using inputs we can define objects that can be passed as an argument instead of having lots of arguments that are responsible for passing one property at the time.
enum Currency {
USD,
GBP
}
input PriceInput {
currency: Currency!
amount: Float!
}
input ProductInput {
name: String!
description: String
price: PriceInput!
categories: [ID!]!
}
input CategoryInput {
name: String!
products: [ID!]!
}
input OrderInput {
products: [ID!]!
purchaserEmail: AWSEmail!
}
type Mutation {
placeOrder(input: OrderInput!): Order!
createProduct(input: ProductInput!): Product!
createCategory(input: CategoryInput!): Category!
startProcessingOrder(id: ID!): Order!
completeOrder(id: ID!): Order!
}Serverless framework setup
As a first step let's define serverless plugin. It will be identical to the one described in this article.
AppSync API definition
When schema is defined and ready to be used we can move forward to defining of the AppSync API withing serverless framework. We start with installation of the serverless-appsync-plugin that simplifies the process and creates abstraction over raw cloudformation types. All that we need to do is to provide a list of resolvers and data sources and plugin will do the rest.
Warning
appSync:
name: secure-graphql-api
schema: src/api/schema.graphql
authentication:
type: API_KEY
apiKeys:
- name: WebClientApiKey
expiresAfter: 1M
resolvers:
Query.getOrders:
kind: UNIT
dataSource: getOrdersDataSource
Mutation.placeOrder:
kind: UNIT
dataSource: placeOrderDataSource
# ...rest of queries and mutations defined in the same way
dataSources:
getOrdersDataSource:
type: AWS_LAMBDA
config:
functionArn: !GetAtt GetOrdersLambdaFunction.Arn
placeOrderDataSource:
type: AWS_LAMBDA
config:
functionArn: !GetAtt PlaceOrderLambdaFunction.Arn
# ...rest of data source defined in the same wayNested fields resolvers are defined in a such way:
appSync:
# ... other properties
resolvers:
# ... other resolvers
getProductCategories:
type: Product
field: categories
kind: UNIT
dataSource: categoriesDataSource
getCategoryProducts:
type: Category
field: products
kind: UNIT
dataSource: productsDataSourceCreating persistance layer
For persistance layer similar setup will be used as described in this article.
DynamoDB indexes
Only major difference is in OrderTable where concept of GSI is used. Index is used to improve application read performance by allowing for querying the table using alternate attributes. In DynamoDB there are two types of indexes:
- Global Secondary Index (GSI) - they can have a different partition and sort key then table's primary key, therefore they are applied to the whole table instead of single partition.
- Local Secondary Index (LSI) - they share the same partition key as the table's primary key but has a different sort key, therefore it provides additional query capabilities within the same partition.
Although additional indexes provides more querying possibilities and can enhance app performance it comes with some trade-offs: they increase storage and write costs, as DynamoDB maintains additional copies of indexed data.
Let's proceed to creation of DynamoDB index
OrderTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: ${self:custom.resourceSlug}-order-table
BillingMode: PAY_PER_REQUEST
AttributeDefinitions:
- AttributeName: purchaserEmail
AttributeType: S
- AttributeName: id
AttributeType: S
- AttributeName: created
AttributeType: S
KeySchema:
- AttributeName: id
KeyType: HASH
GlobalSecondaryIndexes: # Here GSI and its properties is defined
- IndexName: byEmailAndCreatedDate
KeySchema:
- AttributeName: purchaserEmail
KeyType: HASH
- AttributeName: created
KeyType: RANGE
Projection:
ProjectionType: ALLIn the code repository query is utilized in such a way.
async findAllByPurchaserEmail(
email: Order["purchaserEmail"]
): Promise<Order[]> {
const command = new QueryCommand({
TableName: this.tableName,
IndexName: "byEmailAndCreatedDate", // Index usage
KeyConditionExpression: "purchaserEmail = :purchaserEmail",
ExpressionAttributeValues: {
":purchaserEmail": email,
},
});
const { Items } = await this.docClient.send(command);
return Items as Order[];
}Creating resolvers
With the API definition and persistance layer in place, we can proceed to create the resolvers.
TypeScript types generation
One of the best aspects of using GraphQL is its excellent developer experience. By defining all the entities and their relationships in the schema, TypeScript types can be generated based on it.
Let's start with installing necessary dependencies.
yarn add -D @graphql-codegen/cli @graphql-codegen/typescriptAfter installing dependencies, let's create a configuration file specifying the details of generation. Because AppSync-specific types were used in the schema, additional details need to be appended to the configuration so that it can recognize the properties and determine the end result of generation.
import type { CodegenConfig } from "@graphql-codegen/cli";
const config: CodegenConfig = {
overwrite: true,
schema: ["src/api/schema.graphql", "src/api/aws.graphql"],
generates: {
"src/generated/graphql.ts": {
plugins: ["typescript"],
config: {
scalars: {
AWSEmail: "string",
AWSTimestamp: "string",
},
},
},
},
};
export default config;Also additional GraphQL schema file with AWS definitions must be placed in the project.
scalar AWSTime
scalar AWSDateTime
scalar AWSTimestamp
scalar AWSEmail
scalar AWSJSON
scalar AWSURL
scalar AWSPhone
scalar AWSIPAddress
scalar BigInt
scalar Double
directive @aws_subscribe(mutations: [String!]!) on FIELD_DEFINITION
# Allows transformer libraries to deprecate directive arguments.
directive @deprecated(reason: String!) on INPUT_FIELD_DEFINITION | ENUM
directive @aws_auth(cognito_groups: [String!]!) on FIELD_DEFINITION
directive @aws_api_key on FIELD_DEFINITION | OBJECT
directive @aws_iam on FIELD_DEFINITION | OBJECT
directive @aws_oidc on FIELD_DEFINITION | OBJECT
directive @aws_cognito_user_pools(
cognito_groups: [String!]
) on FIELD_DEFINITION | OBJECTNow all it's left to do is to run the generation comment and output file should be placed in src/generated/graphql.ts path.
Mutation implementation
As a first step, let's create the function definition in the Serverless Framework. Technically, this could be defined in the AppSync config, but my preference is to separate these two aspects. In the API specification, I focus on API-related details such as name, authentication, resolvers, data sources, and other properties. In the function definitions, I concentrate on Lambda-specific properties like names, environment variables, or attached policies.
placeOrder:
handler: src/functions/mutation/placeOrder/placeOrder.handler
environment:
ORDER_TABLE: !Ref OrderTable
PRODUCT_TABLE: !Ref ProductTable
iamRoleStatements:
- Effect: Allow
Action:
- dynamodb:PutItem
Resource: !GetAtt OrderTable.Arn
- Effect: Allow
Action:
- dynamodb:GetItem
Resource: !GetAtt ProductTable.ArnThis resolver is just a TypeScript lambda function that executes necessary business logic and returns Order object that has the same structure as defined in schema.
const orderRepository: OrderRepository = new DynamoOrderRepository();
const productRepository: ProductRepository = new DynamoProductRepository();
export const handler: AppSyncResolverHandler<
MutationPlaceOrderArgs,
Mutation["placeOrder"]
> = async (event) => {
const { products: productsInput, purchaserEmail } = event.arguments.input;
if (productsInput.length === 0) {
throw new Error("Order must have at least one product assigned to it");
}
const productWriteModels = await productRepository.findTransactionalByIds(
productsInput
);
const summedAllCurrencies = productWriteModels.reduce<Record<string, number>>(
(acc, { price }) => {
if (acc[price.currency]) {
return {
...acc,
[price.currency]: acc[price.currency] + price.amount,
};
}
return { ...acc, [price.currency]: price.amount };
},
{}
);
const totalPrice = Object.keys(summedAllCurrencies)
.map((key) =>
formatPrice({
currency: key as Currency,
amount: summedAllCurrencies[key],
})
)
.join(", ");
const products: Product[] = productWriteModels.map(
({ price, categories, ...product }) => ({
...product,
// Here we must assert type ourself as the categories property is later on picked up by category field resolver
categories: categories as unknown as Category[],
price: formatPrice(price),
})
);
const order: Order = {
id: v4(),
created: new Date().toISOString(),
products,
purchaserEmail,
status: OrderStatus.Pending,
totalPrice,
};
await orderRepository.create(order);
return order;
};Query implementation
Each subsequent resolver follows the same pattern: first, a function is defined in the Serverless framework, and then the actual Lambda code is written to return the appropriate entity.
For example this is a getOrders query implementation.
getOrders:
handler: src/functions/query/getOrders/getOrders.handler
environment:
ORDER_TABLE: !Ref OrderTable
iamRoleStatements:
- Effect: Allow
Action: dynamodb:Query
Resource: !Sub ${OrderTable.Arn}/index/byEmailAndCreatedDateHelpful Tip
const orderRepository: OrderRepository = new DynamoOrderRepository();
export const handler: AppSyncResolverHandler<
QueryGetOrdersArgs,
Query["getOrders"]
> = async (event) => {
return orderRepository.findAllByPurchaserEmail(event.arguments.email);
};Testing
Let's proceed to test the application. For this purpose, several methods can be utilized, such as sending a request via Postman. However, for simple cases, I use the built-in AppSync GraphQL playground which automatically uses the generated API key as the authorization method.
Let's start with creation of the categories and the products.
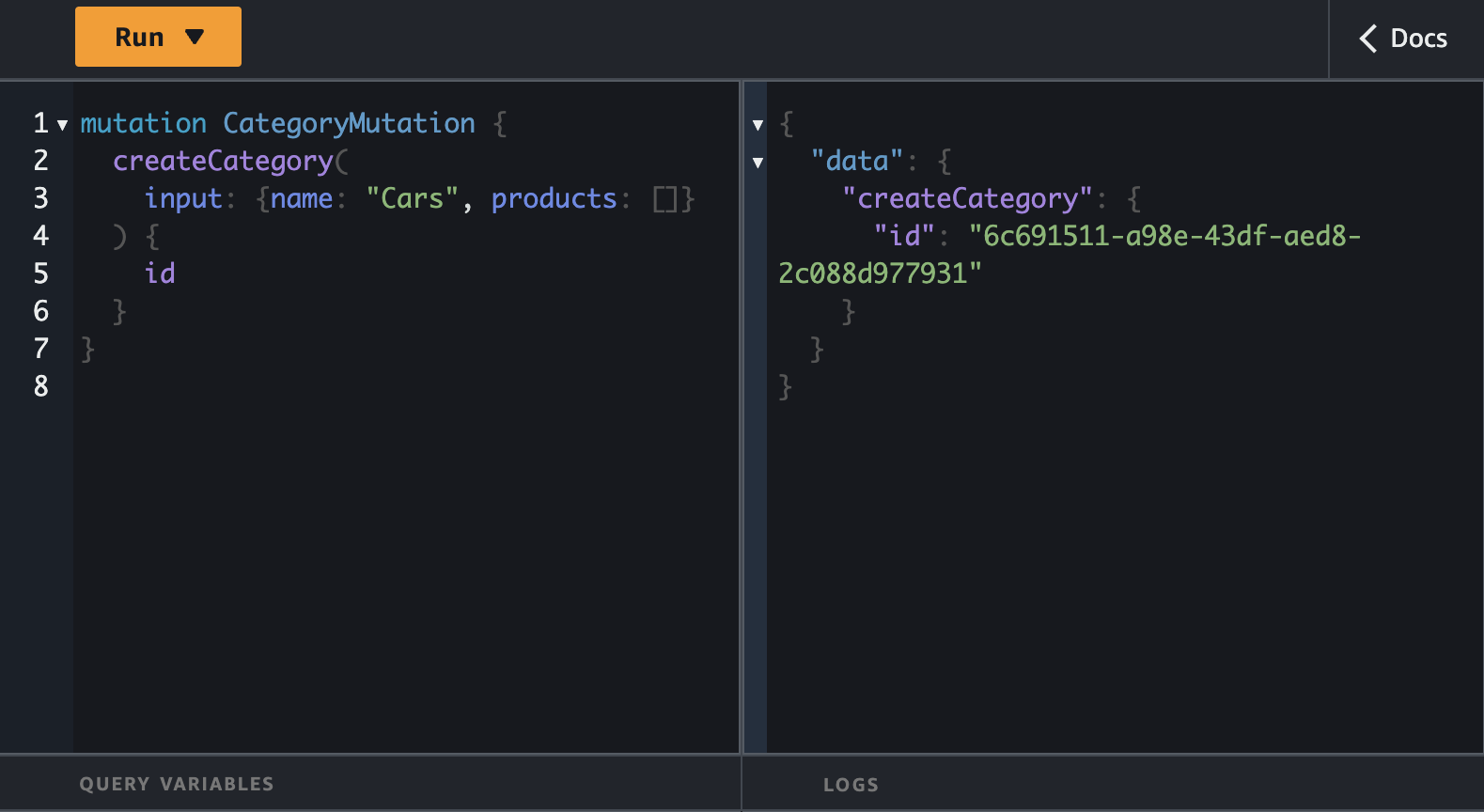
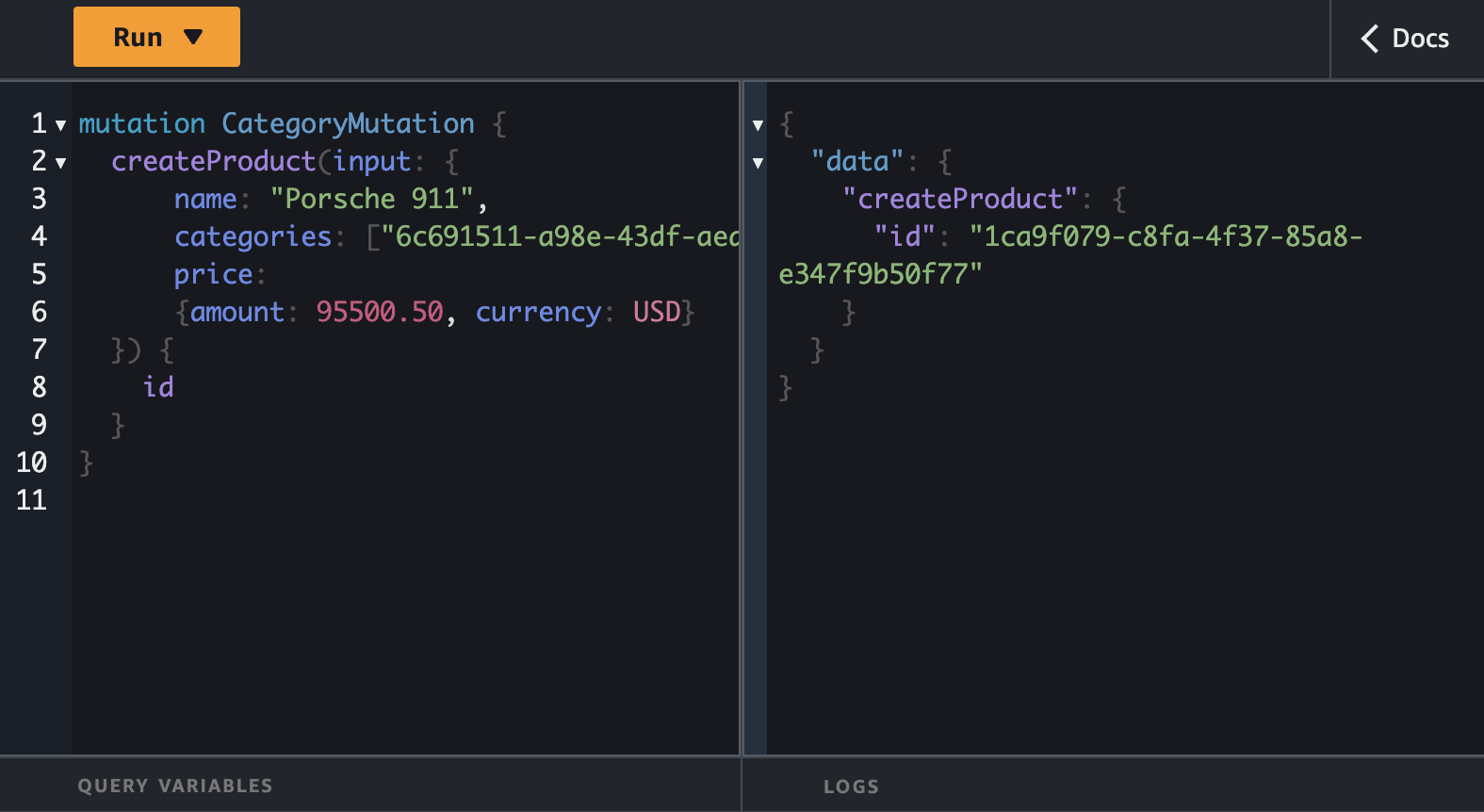
Let's fetch all the products and categories at the same using GraphQL superpowers to make this happen in one call.
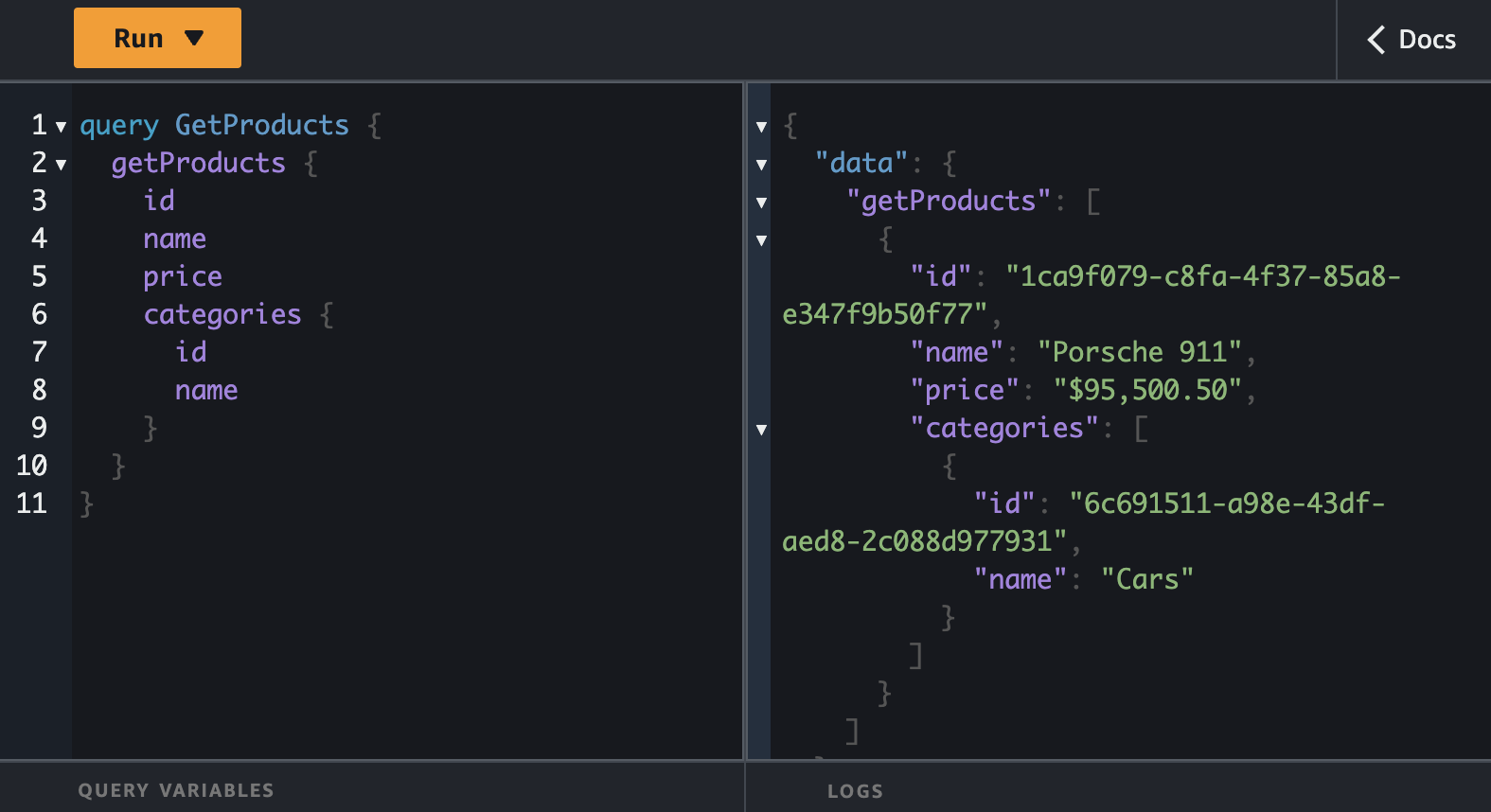
Let's proceed to placing an order.
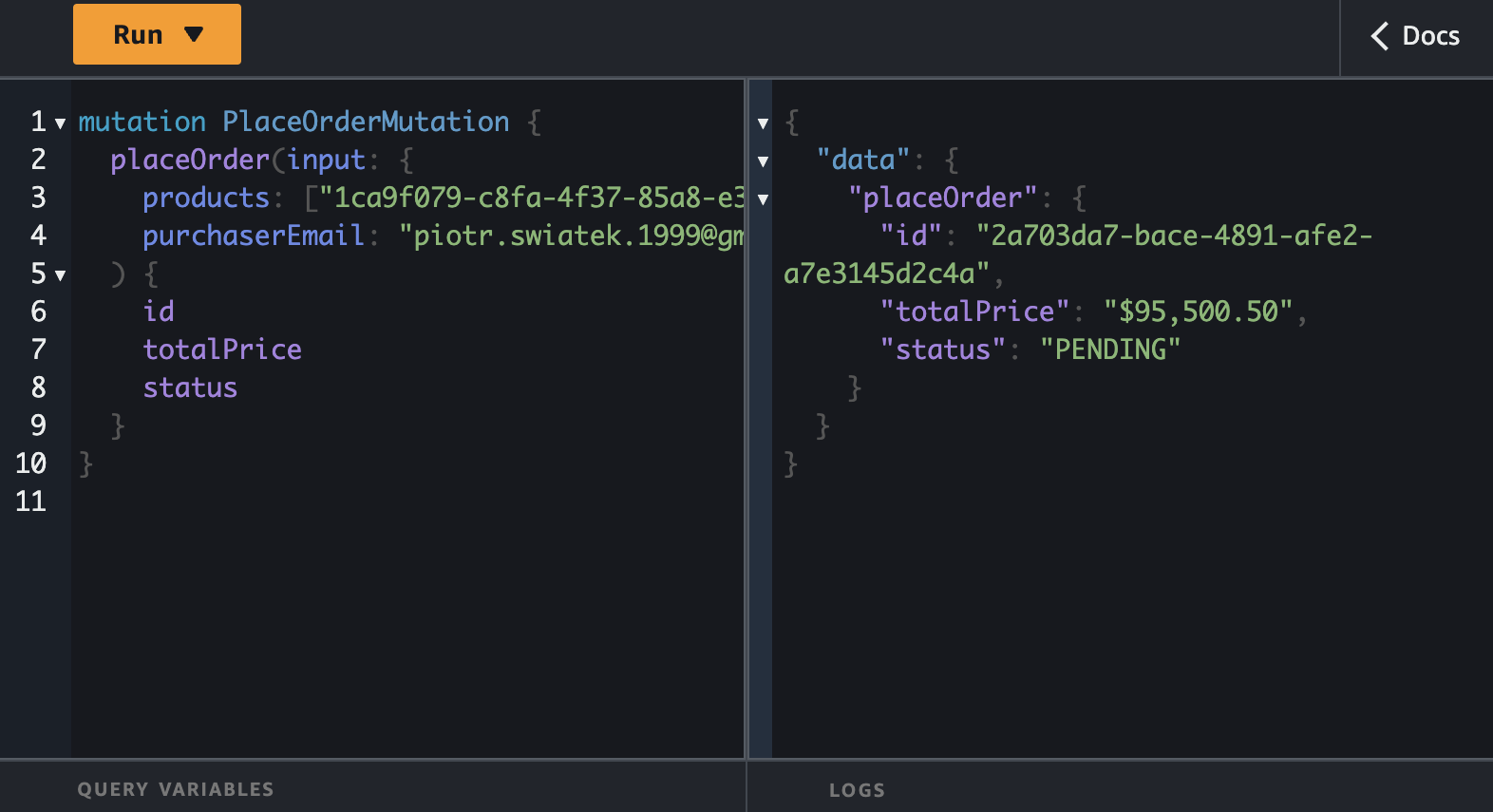
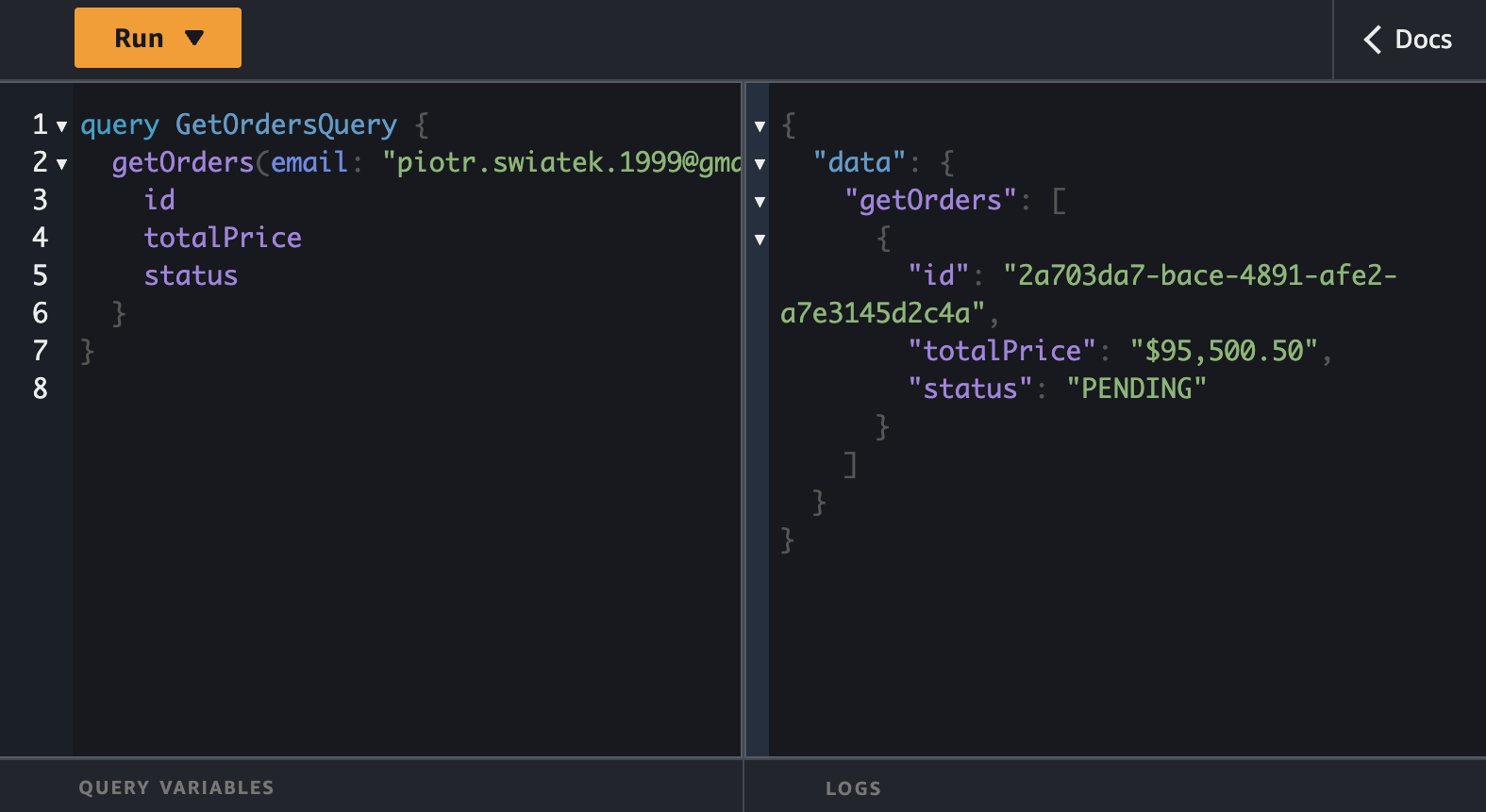
Once order is placed, let's fetch my orders.
Conclusions
First and foremost, this is part 1, covering only API creation. Part 2 focuses on security aspects. This means that, for now, this API is intentionally made insecure and is not production-ready. Apart from that I really do love GraphQL, after fixing some issues like N+1 queries or incomplete support from some development tools it has become my preferred method for building client-facing APIs. For server-to-server communication RPC is still a GOAT but for client calls the ease of selecting the data, tools around it (like Apollo Client or codegen used in this tutorial), lots of learning resources about it and backing from major companies makes it a perfect choice.
With that being said, this article only covers basic concepts about GraphQL. I highly encourage you to expand your knowledge by following some great blogs about GraphQL, such as:


